NumPyのpartiton()は、配列の要素のうち、任意の値k を基準にして、それより小さい値を左側に、それより大きい値を右側に再配置する関数です。”partition” は「仕切り」という意味です。つまり、配列を任意の値k で仕切って再配置するという意味です。
これを使うことで、例えば、配列の中の k番目に小さい値を取得するといった複雑な操作ができるようになります。あまりよく見る関数ではありませんが、確実に操作の自由度が増すので頭に入れておくと良いでしょう。
それではさっそく見ていきましょう。
NumPy配列のソート方法のまとめ
NumPyの配列をソートする上で知っておきたい5つの関数については『NumPyのソート(並び替え)のために知っておきたい5つの方法』でまとめて簡潔に解説しています。ぜひそちらもご確認ください。
1. 書式
まずは書式を確認します。
partition() には関数とメソッドがあります。それぞれ使い方は同じです。しかし np.partition関数は、要素を再配置した新しい配列を作成するのに対して、ndarray.partitionメソッドは元々の配列の要素を再配置するという違いがあります。
書き方:
numpy.partition(a, kth, axis=-1, kind='introselect', order=None)
パラメーター:
| 引数 | 型 | 解説 |
| a | array_like | ソートする配列を渡します。 |
| kth | int または sequence of ints |
配列の再配置の基準とする要素(仕切りとなる要素)を指定します。最小値を0として数えます。そのため、例えば配列の要素の中で2番目に小さな値を基準にする場合はkth=1になります。指定した要素は普通にソートした時と同じ位置に配置され、それより値が小さい要素は前に、値が大きい要素は後ろに配置されます。複数指定することも可能です。 |
| axis* | int or None | 要素を再配置する次元軸を渡します。Noneの場合はソートの前に1次元配列化されます。デフォルトは-1です。この場合は最後の軸に沿ってソートします。 |
| kind* | {‘introselect’} | ソートのアルゴリズムです。使うことはほとんどありません。 |
| order* | str or list of str | 構造化配列を再配置する場合に使います。基準とするフィールドを指定します。 |
| * はオプション引数であることを示します。 | ||
戻り値:
| 要素を再配置した配列:ndarray aと同じdtype, shape の配列を返します。 |
一緒に確認したい関数:
- argpartition: 配列を再配置するインダイスを取得
- sort: 配列の要素をソート
- argsort: 配列の要素をソートしたインダイスを取得
書き方:
ndarray.partition(kth, axis=-1, kind='introselect', order=None)
2. サンプルコード
それではサンプルコードを見ていきましょう。なおオプション引数のkind やorder は使うことはほとんどないので、ここでは割愛します。
以下の配列を使って、np.partitionの使い方を確認していきます。
import numpy as np
a =np.array([ 5, 4, 1, 0, -1, -3, -4, 2])
a
この配列a のkth(何番目に大きい値であるかの順番)は次のようになっています。
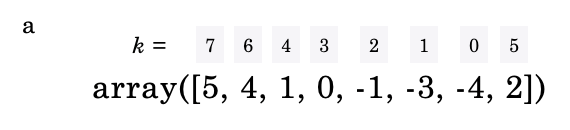
このように最小値から最大値の順に0から数えていきます。1から数えるのではない点にご注意ください。
以下のコードでは、np.paritionを使って、kth=1(=2番目に大きい値。この配列では-3が該当)で仕切って、それより小さい値を左側に、それより大きい値を右側に再配置しています。
np.partition(a, 1)
これは以下の画像のように処理されています。
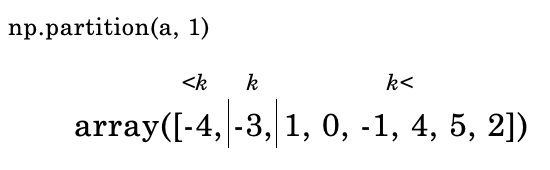
kth=1 より小さな値は左側に、大きな値は右側に再配置されています。
それでは、kth=3(4番目に大きい値。この配列では0が該当)で仕切るとどうなるでしょうか。次のコードで確かめてみましょう。
np.partition(a, 3)
これは以下の画像のように処理されています。
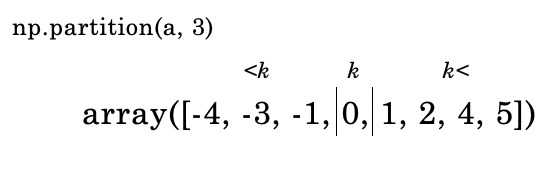
kth=3 より小さな値は左側に、大きな値は右側に再配置されています。
それでは、kth を2つ指定するとどうなるでしょうか。以下のコードをご確認ください。
np.partition(a, (2, 5))
これは以下の画像のように処理されています。
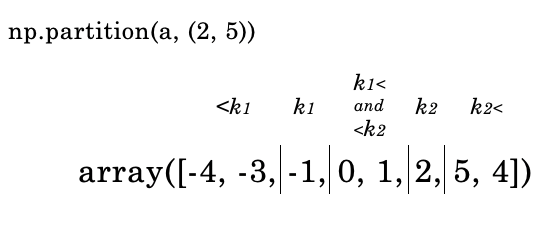
問題
それでは、np.partitionを活用して問題を解いてみましょう。まず、以下の多次元配列があるとします。
import numpy as np
rng = np.random.default_rng()
a = rng.integers(-30, 31, (3, 5))
a
この配列を対象に、以下の条件に合致する数値を取得してください。
- 配列全体の要素のうち2番目に小さな値
- 2行目の中で3番目に小さな値
- 3列目の中で2番目に小さな値
ただ最小値を求めるだけなら、np.aminで可能です。しかし、k番目に小さな値を求めるにはどうすればよいでしょうか。
以下が解答です。
# 配列全体の要素のうち2番目に小さな値を取得
np.partition(a, 1, axis=None)[1]
# 2行目の中で3番目に小さな値を取得
np.partition(a[1], 2)[2]
# 3列目の中で2番目に小さな値を取得
np.partition(a[:,2], 1)[1]
3. まとめ
以上が、NumPyのpartiton()の使い方です。あまり目にする関数ではありませんが、これを知っておくとより自由にデータを操作できることがお分かり頂けたと思います。ぜひ、頭にいれておいてください。
なお、NumPyにはargpartition()という配列再配置のためのインダイスを取得する関数もあります。インダイスを使うと、より豊富な操作が可能になります。こちらについては『NumPyのargpartition()で配列の要素を再配置するインデックスを取得』で解説しています。

コメント