
Pythonで文字列を抽出する方法は、いくつかあります。ここでは、知っておくと便利な4つの方法を解説します。
- インデクシングとスライシング(最も基本)
- match関数を使って先頭の一致する文字列を抽出
- search関数を使って全体の中で最初に一致する文字列を抽出
- findall関数を使って、一致する全ての文字列を抽出
初心者の方は、最も基本となるインデックス、スライシングをしっかりとマスターして下さい。
後半で解説する 3 つの関数は、「正規表現」というものを使って、より複雑な条件で、文字列を抽出するためのものです。これらは、必要に応じて、調べられるようにしておくとよいです。
いずれにせよ、正規表現は、プログラミング初学者の段階では、分からなくても全く問題ありませんので、ここでは流し読みでも構いません。コードを書く経験を続けていれば、後になって読み返した時にすんなりと理解できるようになります。
それでは解説を始めたいと思います。
1. Pythonの文字列抽出の基礎
Pythonの文字列の抽出方法を知るには、まず最初に「インデクシング(= データの格納)」を理解しておく必要があります。
「インデクシング」とは「データの格納のされ方」のことです。つまり、インデクシングを理解するということは、Python上で文字列データが、どのように格納されているのかを理解するということを意味します。
これを知って、初めて、自由自在に文字列を抽出できるようになります。
それでは見ていきましょう。
1.1. 文字列のインデクシング(格納)とは
Pythonで、文字列を作ると、それぞれの文字にインデックス番号が割り振られます。そのインデックス番号を使って、文字列を抽出することができます。
例として、以下の文字列を作ります。
s = 'Hello World.'
print(s)
この文字列には、次のようにインデックス番号が割り振られます。
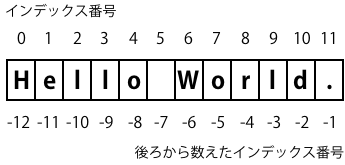
インデックス番号は、前から数える場合は0から、後ろから数える場合は-1から始まります。ここは重要な点なので覚えておきましょう。
これを利用して、文字列を抽出していきます。
1.2. 文字列のスライシング(抽出)とは
文字列の抽出(スライシング)とは、上述のインデクシングの仕組みを利用して、文字列の中の任意の文字を取り出すことです。
文字列の抽出(スライシング)には、以下の構文を使います。
文字列[インデックス番号]
ブラケット [] で囲って、その中にインデックス番号を入力するだけです。
例を見ていきましょう。
# 前から数えたインデックス番号で抽出
s[0]
# 後ろから数えたインデックス番号で抽出
s[-4]
簡単ですね。
ここから、様々なスライシングの方法を例を見ながら説明していきたいと思います。
1.2.1. 指定の箇所まで抽出(スライシング)
コロン( : ) を使うと、インデックスされている要素を特定の箇所まで呼び出すことができます。
以下が基本構文です。
文字列[開始位置:終了位置]
次の例をご覧ください。
# 開始位置だけを指定すると、そこから最後まで抽出します。
s[1:]
# 終了位置だけを指定すると、最初からそこまで抽出します。
s[:3]
#開始位置と終了位置の両方を指定することもできます。
s[3:7]
#後ろから数えたインデックス番号も使えます。
s[-6:-1]
スライシングは開始位置は含み、終了位置は含まない
ここで注目して頂きたいことがあります。それは、開始位置は、そこで指定した要素を含めて始まるのに対し、終了位置は、指定した要素は含まないということです。
例えば、「s[3:7]」では、インデックス番号3番から6番が抽出されます。
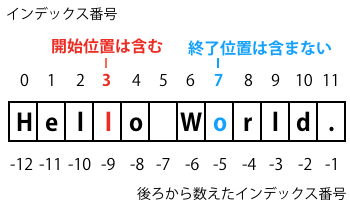
開始位置は含まれ、終了位置は含まれないと覚えておきましょう。
1.2.2. 数文字置きに抽出(スライシング)
コロン(:)を2個つなげると1要素おきや2要素おきに呼び出すことができます。
以下が基本構文です。
文字列[開始位置:終了位置:ステップ]
ステップに何文字置きで抽出したいかを数字で入力します。2文字置きなら2、3文字置きなら3です。
次の例をご覧ください。
#2文字間隔で抽出する。
s[::2]
#後ろから抽出する。
s[::-1]
#後ろから3文字間隔で抽出する。
s[::-3]
#開始位置、終了位置、ステップを同時に指定する。
s[1:9:2]
2. 正規表現を使った文字列の抽出【中上級向け】
ここからは、正規表現を使った、より複雑な文字列の抽出を扱っていきます。内容的に中上級者向けになりますので、初心者の方は、現段階で無理に理解しようとする必要はありません。
しかし、将来的に必要になった時に、「そういえば正規表現っていうものがあったな」と興味のアンテナを張れるようになって頂きたいという意図で、あえて、ここで解説しておきたいと思います。
それでは解説していきます。
正規表現を使うと、より複雑な条件で、文字列を抽出できるようになります。例えば、[a-z]と書くと、小文字のアルファベットでできている文字列の全てを対象とすることができます。4桁の数値でできている文字列を確認したい場合は、[0-9]{4}と書きます。正規表現のパターンは「正規表現一覧」と「サルにもわかる正規表現」で、ほぼ一通り、確認することができますので、ぜひ目を通してみてください。
2.1. match関数 – 先頭が一致する文字列を抽出 –
match関数は、対象となる文字列の先頭に、任意の文字列と一致するものが存在するかどうかを判定する関数です。
match関数の基本構文は以下の通りです。
import re #reモジュールのインポート
re.match("抽出したい文字列(正規表現)", 対象の文字列)
まず、match 関数は re モジュールの関数なので、最初に “import re” でモジュールを読み込んでおく必要があります。モジュールについては、「Pythonのモジュールとよく使うもの一覧」で解説しています。
そして、第一引数に、抽出したい文字列を正規表現パターンで入力します。
それでは実際に見てみましょう。
text = "123-4567 東京都港区虎ノ門"
import re
post_code = re.match("[0-9]{3}-[0-9]{4}" , text)
print (post_code)
抽出したい文字列に「“[0-9]{3}-[0-9]{4}“」という正規表現を入力しています。これは、「数字3桁-数字4桁」の構成の文字列、つまり郵便番号と同じ構成の文字列を抽出対象として指定しているということです。
結果は、<_sre.SRE_Match object; span=(0, 8), match=’123-7777′> という形式で出力されています。
「span=(0,8)」は、対象となる文字列が、インデックス番号の0から8にあることを示しています。「match=’123-4567’」は、対象となる文字列が、123-4567であることを示しています。
このような形式の戻り値を「マッチオブジェクト」と言います。
マッチオブジェクトについての補足
余談ですが、マッチオブジェクトでは、次のように、見たい対象ごとに抽出することもできます。
match_object = re.match(r"[0-9]{3}-[0-9]{4}" , text)
print(match_object.group())
print(match_object.span())
print(match_object.start())
print(match_object.end())
マッチオブジェクトを使うと、このように、それぞれのマッチした結果に対して何らかの処理や判定を組み込めるようになります。使いこなせるようになると、コーディングでできることが広がるので、ぜひチャレンジしてみてください。
なお、対象となる文字列がない場合は、次のように「None」と返されます。
import re
post_code = re.match(r"[a-z]+" , text)
print (post_code)
「r“[a-z]+“」は、小文字のアルファベットが連続しているものという意味の正規表現です。対象の文字列内に、小文字アルファベットの単語はありませんので「None」と返されます。
「r“[a-z]+”」の先頭の「r」は、Pythonの raw string 記法というものです。シンプルに正規表現で文字列を指定するときは、デフォルトで入れておくべきものだとお考えください。r をつけた場合とつけない場合にどうなるかは「【Python 3系】re.subでの置換方法」で検証されていますので、確認しておいて下さい。
2.2. search関数 – 全体の中で最初に一致した文字列を抽出 –
search関数は、文字列全体の中で、最初に条件に一致した文字列を抽出します。上記の match 関数は、対象文字列の先頭のみを対象としているのに対して、こちらは、対象の文字列全体の中から抽出してくれます。
search関数の基本構文は次の通りです。
import re #reモジュールのインポート
re.search(抽出したい文字列(正規表現), 対象の文字列)
match関数と同様に、seach関数も re モジュールの関数なので、最初に “import re” でモジュールを読み込んでおく必要があります。モジュールについては「Pythonのモジュール」でご確認ください。
例を見てみましょう。
text = "東京都港区虎ノ門 123-4567"
import re
post_code = re.search("[0-9]{3}-[0-9]{4}" , text)
print (post_code)
説明が、上述のmatch関数と被りますが、抽出したい文字列に「“[0-9]{3}-[0-9]{4}“」という正規表現を入力しています。これは、「数字3桁-数字4桁」の構成の文字列、つまり郵便番号と同じ構成の文字列を抽出対象として指定しているということです。
結果は、<_sre.SRE_Match object; span=(9, 17), match=’123-7777′> という形式で出力されています。これを「マッチオブジェクト」形式といいます。
「span=(9, 17)」は、対象となる文字列が、インデックス番号の9から17にあることを示しています。「match=’123-4567’」は、対象となる文字列が、123-4567であることを示しています。
存在しない場合に「None」が返されるのは、match関数と同じです。
import re
post_code = re.search(r"[a-z]+" , text)
print (post_code)
2.3. findall関数 – 全体の中で一致する文字列全てを抽出 –
findall関数は、対象の文字列全体の中から、正規表現で指定したパターンに一致する全ての文字列を、リスト形式で抽出してくれる関数です。
findall関数の基本構文は次の通りです。
import re #reモジュールのインポート
re.findall(抽出したい文字列(正規表現), 対象の文字列)
findall関数も re モジュールの関数です。そのため、最初に “import re” でモジュールを読み込んでおく必要があります。モジュールについては「Pythonのモジュール」でご確認ください。
それでは例を見てみましょう。
text = "東京都港区虎ノ門 123-4567, 東京都渋谷区渋谷 765-4321"
import re
postCode_list = re.findall('[0-9]{3}-[0-9]{4}' , text)
print (postCode_list)
「“[0-9]{3}-[0-9]{4}“」という正規表現で、「数字3桁-数字4桁」、つまり郵便番号と同じ構成の文字列を抽出対象としています。結果を見ると、条件と一致する文字列がリスト形式で出力されていますね。
もし、一致する文字列がない場合は、空のリストを返します。
text = "東京都港区虎ノ門 123-4567, 東京都渋谷区渋谷 765-4321"
import re
postCode_list = re.findall(r'[a-z]+' , text)
print (postCode_list)
対象の文字列の中に、「r'[a-z]+’」つまり、小文字アルファベットの単語はないため、空のリストが返されていますね。
3. まとめ
プログラミング初学者の方は、最初の、インデクシングとスライシングをしっかりと使いこなせるようになりましょう。
それだけでもできることは大きく広がります。
正規表現を使う関数については、今は分からなくても、決して焦らないで下さい。プログラミングへの入門の段階では、初めての概念や考え方だらけなので、自分の頭をプログラミング脳に変えていくのに、少し時間がかかります。
プログラミング脳に切り替えていくには、少しずつでも、コツコツ地道に、コードに触れていくことです。そうすると、自然と理解できるようになっているのですね。
これが、プログラミングは根気といわれる理由です。
正規表現を使った関数を、実際に使用する際は、以下のようにそれぞれの関数の特徴を押さえておきましょう。
- match関数:先頭の文字列が対象、戻り値はマッチオブジェクト形式。
- search関数:文字列全体が対象。最初に見つかったもの抽出。戻り値はマッチオブジェクト形式。
- findall関数:文字列全体が対象。条件に一致したもの全てを抽出。戻り値はリスト形式。
なお、match関数、search関数については、「Pythonの文字列を比較する方法」や、「Pythonの文字列を検索する方法」でも出てきますので、ご興味のある方は、あわせてご確認頂ければと思います。





コメント