2. 実験2:知能観(能力の信念)は変えることができるのか
もし、異なる知能観が、異なるモチベーションのパターンに関係しているなら、生徒たちに、知能は可変だと教えることで、よりポジティブなモチベーションを見せるようになるはずで寿司、結果、より高い達成を実現するはずです。
実験2は、まず媒介モデルを、新しい、より成績の低い被験者サンプルを用いて、より短いコースで行います。次に、春学期に、そのうちの半分の生徒に、暗黙の知能観を教える介入を行い、対象グループとの、モチベーションや達成への効果を見ます。
知能は可変だという考えを教えられた生徒たちは、よりポジティブなモチベーションと、より大きな努力を見せるようになるのでしょうか。そして、彼らは、暗黙の知能観を教えられていない生徒たちと比べて、より高い成績を達成することができるのでしょうか。
2.1. 被験者のデータ
実験2の被験者は、実験1とは異なるニューヨーク市の公立中学校の7年生の生徒たち99人(女性49人、男性50人)です。被験者の52%はアフリカ系アメリカ人で、45%がラテン系、3%が白人とアジア人です。
生徒たちは比較的成績が低く、6年生の最終学期の数学の成績は全国の35パーセンタイル(下位35%)で、79%の生徒は無料ランチの利用者です。最終的に99人の7年生の生徒が、アンケートに参加し、そこから95人の生徒が介入研究に選ばれました。
この95人のうち、5人(実験グループ3人、比較グループ2人)は定期的にセッションに参加することができず、分析から除外しています。そのため最終的には91人の生徒が、知能観の介入実験に参加しています。48人が実験グループで、43人が対照グループです。
なお、2つのグループの生徒たちの元々の成績に顕著な違いはありません。秋学期の数学の成績は、4ポイントスケールで、実験グループが2.38で、対照グループが2.41でした。また、実験前のモチベーション構成にも顕著な違いはありませんでした。
2.2. 測定項目と測定方法
この研究でも、実験1と同じく、数学の成績とモチベーション変数を測定します。
2.2.1. 成績(介入前と後)
6年生の時の数学の成績が、介入前の指標として使われます。そして、7年生の秋学期と春学期の数学の最終成績が、介入後の成績として成長カーブを描くために使われます。
2.2.2. モチベーション変数
実験1と同じアンケートを使って、生徒たちの最初のモチベーションを測定します。知能観、ラーニング・ゴール、努力の信念、失敗への反応としての戦略が、7年生の秋学期の最初に測定されます。
2.3. 介入(暗黙の知能観の講義)の手順
次に、介入(暗黙の知能観の講義)の詳細を見ていきましょう。
介入は、7年生の春学期の最初から始まり、1週間ごとに25分を8回行われました。生徒たちは、学校からランダムに割り当てられたアドバイザリー・クラス(生徒に学習のアドバイスやケアを行うクラス)に12-14人の単位で参加しています。それぞれのアドバイザリー・グループは、ランダムに実験グループ(暗黙の知能観トレーニング)と、対照グループに振り分けられています。
なお、参加生徒たちには、脳について学べて、学習に役立つスキルを教えてもらえて、単位も貰える8週間のワークショップだと伝えられています。
2.3.1. 介入セッションの概要
以下が8つのセッションの概要です(Table5)。

両グループの生徒たちはどちらも、同じように組み立てられたワークショップに参加します。
どちらも、脳生理学、学習スキル、反偏見的な考え方を学びます。加えて、科学的根拠のある文献のリーディング、アクティビティ、ディスカッションを行います。しかし、実験グループの生徒たちは、知能は可変であり成長するものであることを教えられます。対照グループの生徒たちは、記憶に関するレッスンを受けて、それぞれが個人的に関心のあるディスカッションに参加します。
なおこの介入は、チュウ、ホン、ドウェックらの1997年の研究と、アロンソんらの2002年の研究で行われたものをモデルとして手を加えています(※7,8)。
2.3.2. 介入セッションのチーム構成
この介入セッションのために、16人の大学生がアシスタントとしてリクルートされています。彼らは生徒たちのメンターとして働き、モチベーション介入ワークショップの一つを任されます。2人1組のメンターが、ワークショップのリーダーとして働きます。
2.3.3. 介入の効果測定
介入の効果測定として、
- ワークショップの内容の理解度の測定
- 知能観の変化の測定
- モチベーションや振る舞いの変化の測定
- 成績の測定
を行います。
ワークショップの内容の理解度の測定
介入の最後に、両グループの生徒たちは、ワークショップの内容についてクイズを出されます。
いくつかの問題は、両グループで教えられた情報をテストするものです(例:「誰かの外見を評価する時は、経験や記憶、偏見、計画からそれを行う」)。他の問題は、暗黙の知能観グループで教えられたものですが、他のグループの生徒にとっても最もらしいものです(例:「新しいことを学ぶ時、脳で何が起きるか?ニューロンを使い切る/神経細胞のつながりを強化する/脳内物質が使い切られる」)。
生徒たちにはこのクイズの目的は、ワークショップで教えられたことをよりよく理解するためだと伝えられており、成績には影響しないことが伝えられています。そして、クイズに関係なく、単位を得られることも説明されています。
知能観の変化の測定
生徒たちの知能観が、ワークショップによって変わったかどうかを見るために、介入の3週間後に、実験1で使ったものと同じ知能観アンケートが行われています。
モチベーションや振る舞いの変化の測定
数学の教師は、個々人の生徒のモチベーションや振る舞いが、ワークショップの後に変わったかどうか、どのように変わったかを書くように求められました。教師は、もちろん、どの生徒がどちらのグループだったかは知りません。
成績
成績の成長カーブが、3地点(6年生春学期、7年生秋学期、春学期)で計られました。全体としての平均は次の通りです。6年生春学期(M[平均]=2.86, SD[標準偏差]=0.97, range[幅]=0 – 4.33)、7年生秋学期(M=2.33, SD=1.19, range=0 – 4)、7年生春学期 (M=2.11, SD=1.30, range=0 – 4).
2.4. 結果
それでは結果を見ていきましょう。
2.4.1. 簡単な介入で暗黙の知能観を持つことができる
暗黙の知能観介入が実験グループに対して、確かに効果があるということを確認するために、次の3つの効果測定を行いました。
- 内容の理解
- 知能観の変化
- モチベーションの変化
それぞれ見ていきましょう。
内容の理解
もし、介入がうまくいっているなら、暗黙の知能観の理解は実験グループの方が深まっており、知識や脳の構造、学習スキルの理解は実験グループも対照グループも同じぐらい深まっているはずです。
そこで一元配置分散分析(ANOVA)を行いました。結果、全体的なワークショップの内容については、グループに違いはありませんでした(73.0% vs. 70.5%, F=.18, d=.10, ns))。しかし、暗黙の知能観のテストにおいては、実験グループの方が顕著に高い成績をあげました(84.5% vs. 53.9%, F=23.36, d=.95, p<.05)。
加えて、実験グループの、アドバイザリー・クラスごとの暗黙の知能観クイズの結果も分散分析した結果、そこに違いは見られませんでした(F=2.28, ns)。そのため、暗黙の知能観のメッセージは、全ての実験グループに対して効果的に伝わっており、共通の学習内容の理解は実験グループも対照グループも同一じったということです。
知能観の変化
介入によって、実験グループの生徒たちの知能観が変化したかも検証しました。結果、予想通り、ペアT検定によって、実験グループの参加者は、介入の後、より強く暗黙の知能観を持つようになったことを示しています (4.36 vs. 4.95 , Cohen’s d=.66, t=3.57, p<.05)。しかし、対照グループの生徒たちに変化は認められません(4.62 vs. 4.68, Cohen’s d=.07, t=.32, ns)。
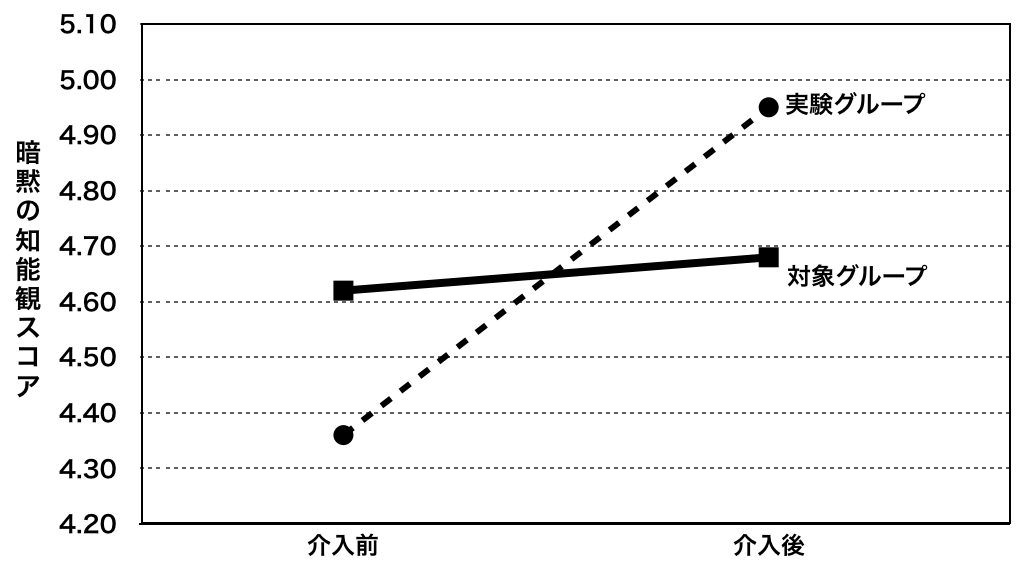
また、二つのグループの変化の度合いが顕著に異なるのかどうかも、[実験 vs. 対照][テスト前、テスト後]の2元配置分散分析で、前後のスコアを反復測定変数としてテストしました。そして実験グループは、対象グループよりも確かに大きな知能観の変化を見せていることが確認されました(F=3.98, p<.05)。そして、介入後、対照グループよりも暗黙の知能観になる傾向が顕著に高いものでした(d =.47; F=4.50,p<.05)。
モチベーションの変化
実験グループでは27%、対象グループでは9%が、教師からポジティブな変化を見せたとコメントされました。これは統計的に顕著な違いと言えます(X2 =4.72, odds ratio=3.26, p<.05)。
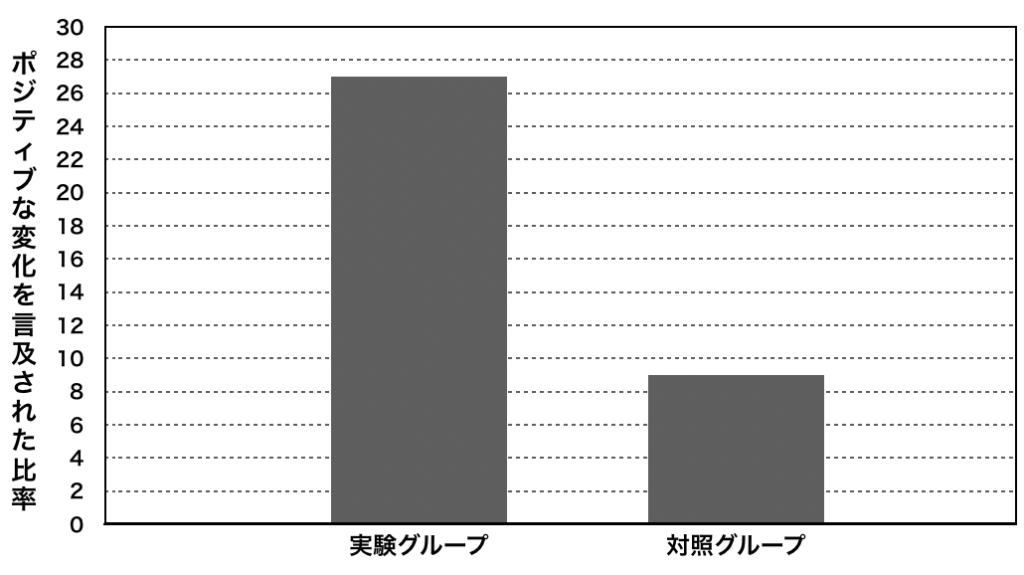
次のものが典型的なコメントです。
「Lは、それまで決して努力をすることはなかったし、宿題も期限通りに提出することはありませんでした。それが、私がレビューをしてから改善できるように、早めに宿題を終わらせようと、遅くまで何時間も頑張るようになりました。彼は、それまで宿題でCかそれ以下しか取ったことがないのですが、B+を取るようになりました。」
「Mの成績は、とても低かったです。しかし、この数週間、彼女は自発的に、テストの解き方を上達させるために、ランチの時間などに、私に質問するようになってきました。彼女の成績は劇的に上昇し、最近のテストでは落第点から84点になりました。」
これらの結果は、簡単な介入で、生徒たちに暗黙の知能観を持たせることができる、ということを示しています。
2.4.2. 暗黙の知能観を持つと顕著に成績が向上する
学業の達成に対する介入の効果を測定するために、生徒たちの数学の成績の成長カーブを調査しました。まず、中学における数学の成績がどのように変わったかを、ブリュックとローデンブッシュらの階層的線形モデルで分析しました(※3.4)。
具体的には、介入が実験グループの数学の過程において転換点であったかどうかを確認することが目的です。そのため、分析において節点(変化点)を作り、介入後、成績の成長カーブに、急な変化があったかどうかを決定します(※9)。
節点の作成は、分析において、いくつかのアドバンテージがあります。節点は、(a)曲線的過程とうまくモデルできない急な変化のタイプをモデルできるようになる、(b)全ての数学の達成データを活かすことができる、(c)介入が数学の成長過程の転換点であるという仮説をテストできる。
そこで、節点の前後に、タイムセグメントのダミーコードを作りました。
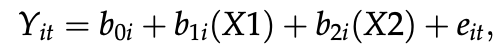
b0は、Time1の数学の平均成績の切片です。X1はダミー変数で、Time1からTime2への数学の成績の変化、X2はTime3からTime3への変化です。そのため、全体の方程式は、数学の成績の最初の水準(b0)、および、Time1からTime2の数学成績の変化(b1)、および、Time2からTime3の数学成績の変化(b2)を表します。つまり、この方程式は、介入前と介入後の成長予測を可能にするものです。
両グループとも、生徒たちは、数学のクラスにランダムに割り当てられています。全ての生徒たちは同じ教師から教えてもらい、同じカリキュラムをこなしています。しかし、潜在的な差異を調整するために、それぞれのクラスにダミー変数を追加しています。
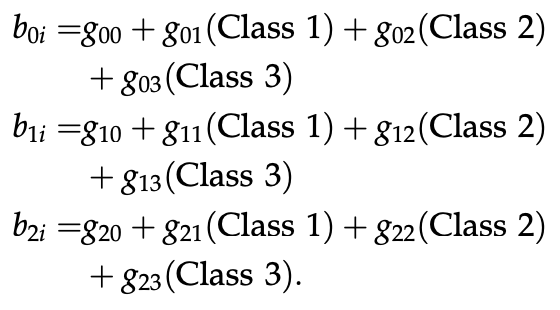
このクラスダミーを入れることで、教室内の雰囲気や生徒同士の関係のような、潜在的な教室ごとの差異を調整した上で、それぞれの介入前後の成長の平均水準を見積もることができます。
数学の成長過程に対する介入の効果を測定する為に、ダミー変数(0=対照グループ、1=実験グループ)を入れています。
結果、対象グループでは、Time1(6年生春)の平均成績は2.72(C+)、Time1からTime2の間の平均成績(7年生秋学期; b= -.34, t=- 4.29, p<.05)と、介入後のTime2からTime3の間の平均成績(7年生春学期; b=- .20, t=-2.61, p<.05)にも、顕著な低下が見られました。
実験グループでは、介入前のTime1の成績において、対象グループと違いはありませんでした(b=.18, t=.83, ns) 。また、同じく介入前のTime1とTime2の間にも、違いはありませんでした(b=-.12, t =- .60, ns)。これは介入前だから当然のことです。
ところが、実験グループで介入後のTime2とTime3の間で、顕著な影響が見られます(b=.53, t=2.93, p<.05)(figure4)。
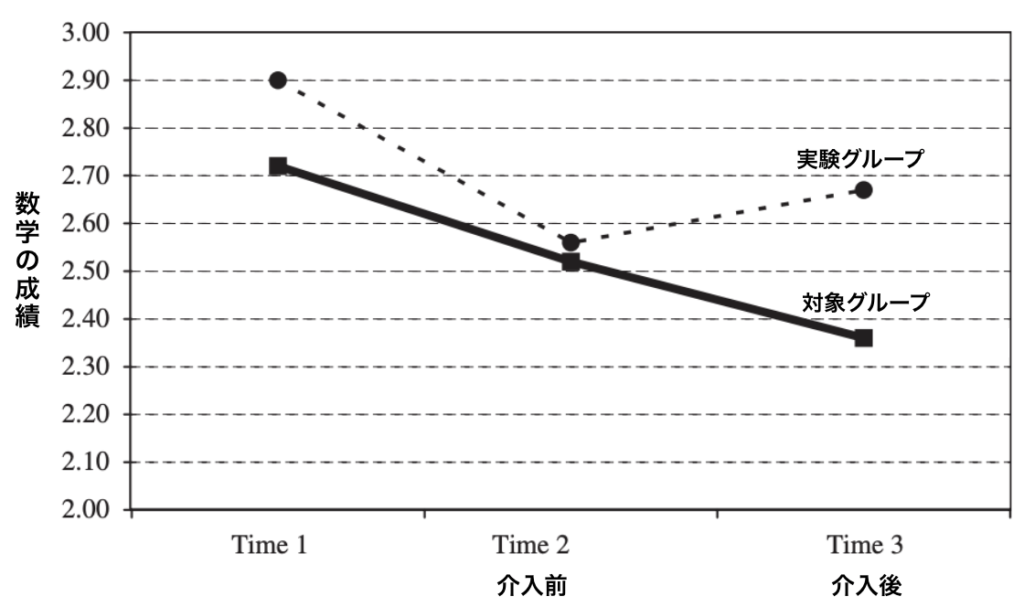
対照グループの生徒に見られる成績の低下は、中学への以降時によく見られるものです(※10)。しかしながら、この下方向の成長カーブは、実験グループでは、ほんの数ヶ月の介入で、暗黙の知能観を教えるだけで止めることができます。
この発見は、具体的に暗黙の知能観が、両グループの生徒たちに平等に影響した実験コンディションの他のモチベーションファクターよりも、達成においてベネフィットをもたらすということを示しています。
キーとなる一つの信念(能力は努力と訓練によって伸ばすことができるという信念)の簡潔な介入だけで、モチベーションと達成に顕著な影響を与えられると結論できます。

コメント